Schema changes are usually critical operations to perform on a high volume database. One thing off, and you are looking at an outage. PostgreSQL has a lot of nice alternatives to make these schema changes safe. However, depending on the kind of schema migration, you would need to know exactly what the alternatives are and perform it exactly in the prescribed way. While you can build some automation around it to make them easy, it still induces cognitive load on a Product Engineer. For instance - While working on a feature set, they have to scout database documentation and best practices to keep every edge case in mind before running the schema change in production.
This is where pg-online-schema-change/pg-osc comes in. My goal with my pg-osc is to have a single tool that you can use to perform any kind of ALTER statement safely (few other nifty features mentioned below), thus reducing the cognitive load and having one blessed way to perform these operations that you can embed in your existing toolchain.
pg-osc is inspired by pt-online-schema-change (MySQL) and the implementation design of pg_repack.
pg-osc uses the concept of shadow tables to perform schema changes. At a high level, it creates a shadow table that looks structurally the same as the primary table, performs the schema change on the shadow table (avoiding any locks since nothing is using this table), copies contents from the primary table to the shadow table and swaps the table names in the end while preserving all changes to the primary table using triggers (via audit table). It looks something like this (detailed steps are listed in the repository readme)
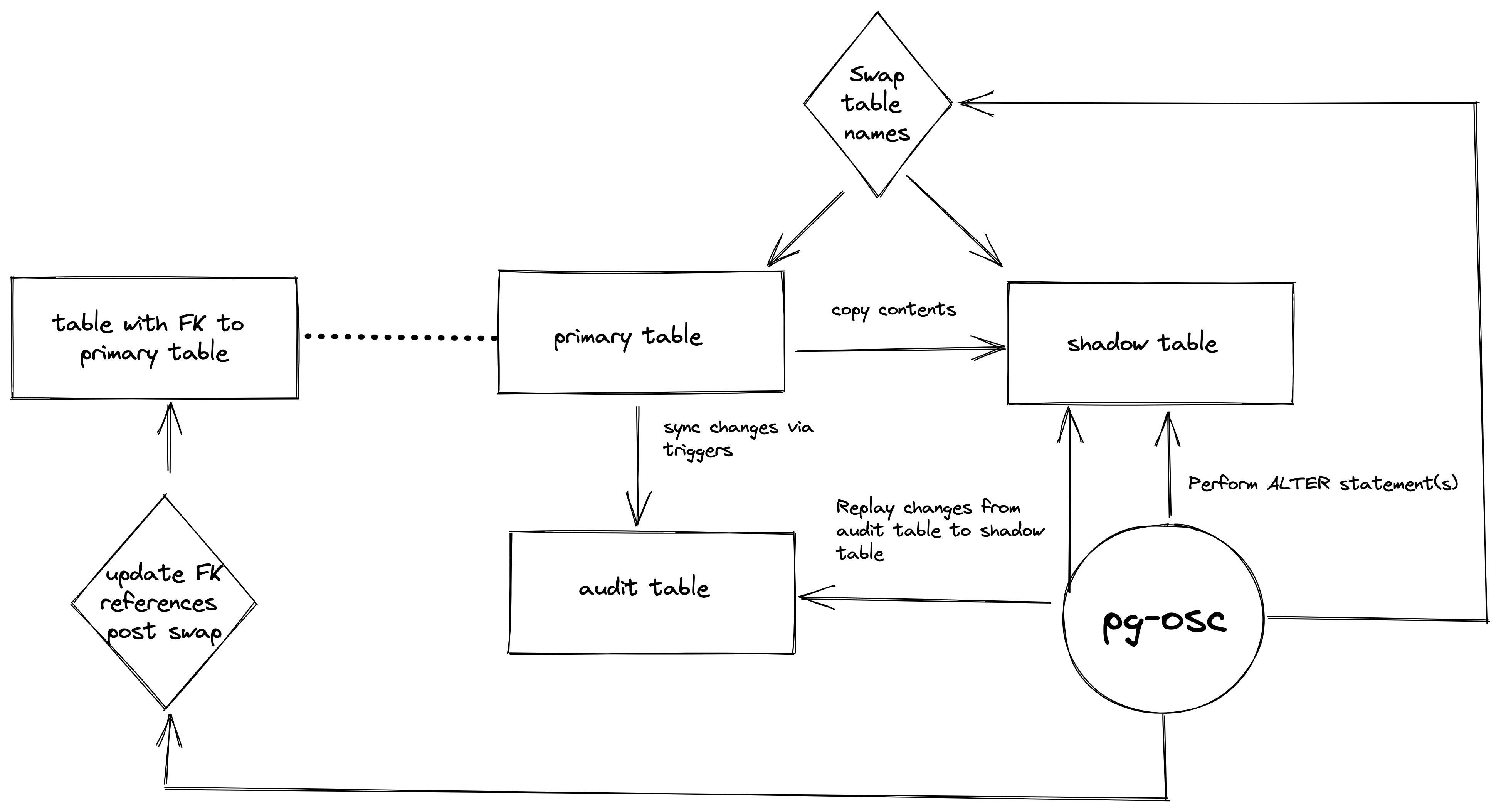
By using a tool like pg-osc you are basically trading off speed for reliability. Since the operation involves copying table, syncing real time data, cutting over and more, depending on the size of the table this can take hours.
Some prominent features
pg-oscsupports when a column is being added, dropped or renamed with no data loss.pg-oscacquires minimal locks throughout the process (be mindful of the caveats).- Copies over indexes and Foreign keys.
- Optionally drop or retain old tables in the end.
- Optionally kill other competing backends (this works similar to
pg_repack) for a quick swap and shadow table setup (more in README). - Backfill old/new columns as data is copied from primary table to shadow table, and then perform the swap using a custom
--copy-statement.
Examples
Multiple ALTER statements
pg-online-schema-change perform \
--alter-statement 'ALTER TABLE books ADD COLUMN "purchased" BOOLEAN DEFAULT FALSE; ALTER TABLE books RENAME COLUMN email TO new_email;' \
--dbname "production_db" \
--host "localhost" \
--username "jamesbond" \
--password "" \
--drop
Kill other backends after 5s
If the operation is being performed on a busy table, you can use pg-osc’s kill-backend functionality to kill other backends that may be competing with the pg-osc operation to acquire a lock for a brief while. The ACCESS EXCLUSIVE lock acquired by pg-osc is only held for a brief while and released after. You can tune how long pg-osc should wait before killing other backends (or if at all pg-osc should kill backends in the first place).
pg-online-schema-change perform \
--alter-statement 'ALTER TABLE books ADD COLUMN "purchased" BOOLEAN DEFAULT FALSE;' \
--dbname "production_db" \
--host "localhost" \
--username "jamesbond" \
--password "" \
--wait-time-for-lock=5 \
--kill-backends \
--drop
Backfill data
When inserting data into the shadow table, instead of just copying all columns and rows from the primary table, you can pass in a custom sql file to perform the copy and do any additional work. For instance - backfilling certain columns. By providing the copy-statement, pg-osc will instead play the query to perform the copy operation. Further instructions in README.
-- file: /src/query.sql
INSERT INTO %{shadow_table}(foo, bar, baz, rental_id, tenant_id)
SELECT a.foo,a.bar,a.baz,a.rental_id,r.tenant_id AS tenant_id
FROM ONLY examples a
LEFT OUTER JOIN rentals r
ON a.rental_id = r.id
pg-online-schema-change perform \
--alter-statement 'ALTER TABLE books ADD COLUMN "tenant_id" VARCHAR;' \
--dbname "production_db" \
--host "localhost" \
--username "jamesbond" \
--password "" \
--copy-statement "/src/query.sql" \
--drop
Tests
Using pg_bench I have tested this to perform schema migrations on a 50M large table that is receiving ~100 TPS with no data loss and not needing to kill the backends. Also simulated an environment where the average transaction duration is 1-2s and was able to perform schema migrations on a 120M large table that is receiving ~40 TPS with no data loss. The later was done with --kill-backends. I plan on introducing the pg_bench test in CI suite as an integration test. Its been helpful to catch edge cases as well.
UPDATE: Published preliminary load test (7K+ writes/s & 12k+ reads/s)
UPDATE: The Github repository now runs a suite of integration and smoke tests as well.
What is Next
- I’d love to support the ability to reverse the change post table name swap with no data loss (tracking issue). This can be very beneficial if you realize something is not right after the operation has ended.
- Now that I see how the fully-fledged program looks like, I think some refactoring and more tests are in order.
- There are also some interesting things you can do by plugging into the trigger and performing actions on certain events.
- Introduce a Docker image to make it easy to run on containers.
- Cleaning up logging a little bit.
- Migrate to prepared statements.
The tool is still early and I consider it experimental. I’d love to hear from you (twitter, github issues or email(shayonj at gmail)) if you have any uses where you are finding or may potentially find pg-osc useful 🙂. To get started, you can head over to the repository, install the gem and get cracking.
If there is something not mentioned here under enhancements, but you would like to see, don’t hesitate to open a ticket.
Last, but not least special thanks to @jfrost for their expertise, PR reviews and brainstorming :).